| How to Use the Kafka Streams API | 您所在的位置:网站首页 › kafka streams › How to Use the Kafka Streams API |
How to Use the Kafka Streams API
|
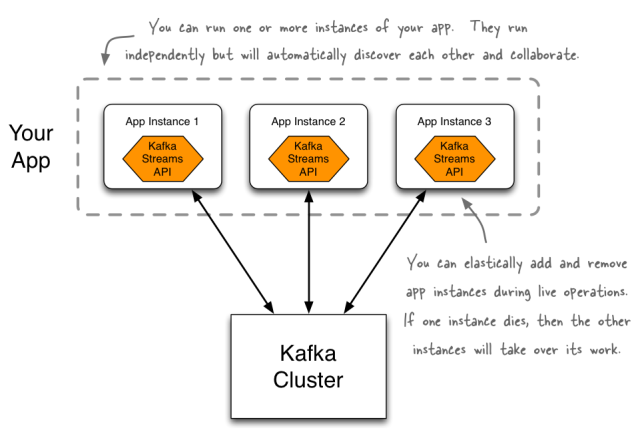
Whenever we hear the word "Kafka," all we think about it as a messaging system with a publisher-subscriber model that we use for our streaming applications as a source and a sink. We could say that Kafka is just a dumb storage system that stores the data that's been provided by a producer for a long time (configurable) and can provide it customers (from a topic, of course). Between consuming the data from producer and then sending it to the consumer, we can’t do anything with this data in Kafka. So we make use of other tools, like Spark or Storm, to process the data between producers and consumers. We have to build two separate clusters for our app: one for our Kafka cluster that stores our data and another to do stream processing on our data. To save us from this hassle, the Kafka Streams API comes to our rescue. With this, we have a unified Kafka where we can set our stream processing inside the Kafka cluster. And with this tight integration, we get all the support from Kafka (for example, topic partition becomes stream partition for parallel processing). What Is the Kafka Streams API?The Kafka Streams API allows you to create real-time applications that power your core business. It is the easiest to use yet the most powerful technology to process data stored in Kafka. It gives us the implementation of standard classes of Kafka. A unique feature of the Kafka Streams API is that the applications you build with it are normal applications. These applications can be packaged, deployed, and monitored like any other application, with no need to install separate processing clusters or similar special-purpose and expensive infrastructure!
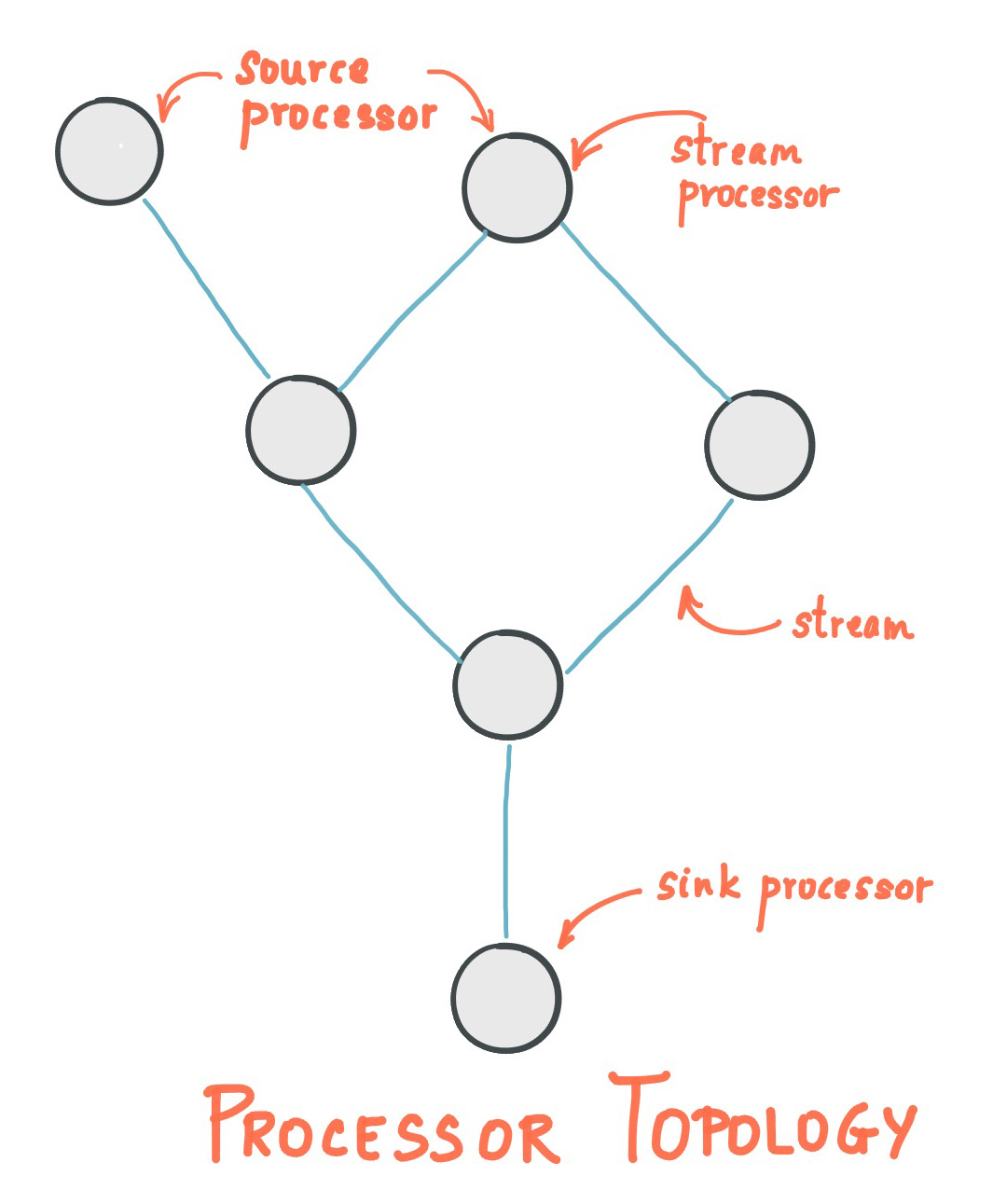
Source Features BriefThe features provided by Kafka Streams: Highly scalable, elastic, distributed, and fault-tolerant application. Stateful and stateless processing. Event-time processing with windowing, joins, and aggregations. We can use the already-defined most common transformation operation using Kafka Streams DSL or the lower-level processor API, which allow us to define and connect custom processors. Low barrier to entry, which means it does not take much configuration and setup to run a small scale trial of stream processing; the rest depends on your use case. No separate cluster requirements for processing (integrated with Kafka). Employs one-record-at-a-time processing to achieve millisecond processing latency, and supports event-time based windowing operations with the late arrival of records. Supports Kafka Connect to connect to different applications and databases. StreamsA stream is the most important abstraction provided by Kafka Streams. It represents an unbounded, continuously updating data set. A stream is an ordered, replayable, and fault-tolerant sequence of immutable data records, where a data record is defined as a key-value pair. It can be considered as either a record stream (defined as KStream) or a changelog stream (defined as KTable or GlobalKTable). Stream ProcessorA stream processor is a node in the processor topology. It represents a processing step in a topology (to transform the data). A node is basically our processing logic that we want to apply on streaming data.
Source As shown in the figure, a source processor is a processor without any upstream processors and a sink processor that does not have downstream processors. Processing in Kafka StreamsThe aim of this processing is to provide ways to enable processing of data that is consumed from Kafka and will be written back into Kafka. Two options available for processing stream data: High-level Kafka Streams DSL. A lower-level processor that provides APIs for data-processing, composable processing, and local state storage. 1. High-Level DSLHigh-Level DSL contains already implemented methods ready to use. It is composed of two main abstractions: KStream and KTable or GlobalKTable. KStreamA KStream is an abstraction of record stream where each data is a simple key value pair in the unbounded dataset. It provides us many functional ways to manipulate stream data like map mapValue flatMap flatMapValues filterIt also provides joining methods for joining multiple streams and aggregation methods on stream data. KTable or GlobalKTableA KTable is an abstraction of a changelog stream. In this change log, every data record is considered an Insert or Update (Upsert) depending upon the existence of the key as any existing row with the same key will be overwritten. 2. Processor APIThe low-level Processor API provides a client to access stream data and to perform our business logic on the incoming data stream and send the result as the downstream data. It is done via extending the abstract class AbstractProcessor and overriding the process method which contains our logic. This process method is called once for every key-value pair. Where the high-level DSL provides ready to use methods with functional style, the low-level processor API provides you the flexibility to implement processing logic according to your need. The trade-off is just the lines of code you need to write for specific scenarios. Code in Action: QuickstartTo start working on Kafka Streams, the following dependency must be included in the SBT project: "org.apache.kafka" % "kafka-streams" % "0.11.0.0"Following imports are required for the application: import org.apache.kafka.common.serialization.{Serde, Serdes} import org.apache.kafka.streams.KafkaStreams import org.apache.kafka.streams.StreamsConfig._ import org.apache.kafka.streams.kstream.{KStream, KStreamBuilder}Next, we have to set up some configuration properties for Kafka Streams val streamsConfiguration = new Properties() streamsConfiguration.put(APPLICATION_ID_CONFIG, "Streaming-QuickStart") streamsConfiguration.put(BOOTSTRAP_SERVERS_CONFIG, "localhost:9092") streamsConfiguration.put(DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String.getClass.getName) streamsConfiguration.put(DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String.getClass.getName)Now we have to create an instance of KStreamBuilder that provides us with a KStream object: val builder = new KStreamBuilderThe builder object has a Stream method that takes a topic name and returns an instance of the kStream object subscribed to that specific topic: val kStream = builder.stream("InTopic")Here on this kStream object, we can use many methods provided by the high-level DSL of Kafka Streams like ‘map’, ‘process’, ‘transform’, ‘join’ which in turn gives us another KStream object with that method applied. And now the last step is to send this processed data to another topic val upperCaseKStream = kStream.mapValues(_.toUpperCase) //characters of values are now converted to upper case upperCaseKStream.to("OutTopic") //sending data to out topicThe last step is to start the streaming. For this step, we use the builder and the streaming configuration that we created: val stream = new KafkaStreams(builder, streamsConfiguration) stream.start()This is a simple example of high-level DSL. For clarity, here are some examples. One example demonstrates the use of Kafka Streams to combine data from two streams (different topics) and send them to a single stream (topic) using the High-Level DSL. The other shows filtering data with stateful operations using the Low-Level Processor API. Here is the link to the code repository. ConclusionWith Kafka Streams, we can process the stream data within Kafka. No separate cluster is required just for processing. With the functionality of the High-Level DSL, it's much easier to use — but it restricts how the user to processes data. For those situations, we use Lower-Level Processor APIs. I hope this article was of some help! References Apache Kafka documentation on Streams Confluent documentation on Streams |
【本文地址】